

全球首个基于 NVIDIA A100 的 AI 系统
NVIDIA DGX ™ A100 是适用于所有 AI 工作负载的通用系统,在全球首个 5 petaFLOPS AI 系统中提供前所未有的计算密度、性能和灵活性。NVIDIA DGX A100 采用世界上最先进的加速器 NVIDIA A100 Tensor Core GPU,使企业能够将训练、推理和分析整合到统一、易于部署的 AI 基础设施中,包括直接访问 NVIDIA AI 专家。
AI 数据中心的基本构建块
一种更简单、更快速的人工智能解决方法
NVIDIA AI Starter Kit 提供您团队所需的一切——从世界一流的 AI 平台到优化的软件和工具,再到咨询服务——让您的 AI 计划快速启动和运行。不要浪费时间和金钱来构建 AI 平台。一天内插入并通电,一周内获得定义的用例,并更快地开始生产模型。

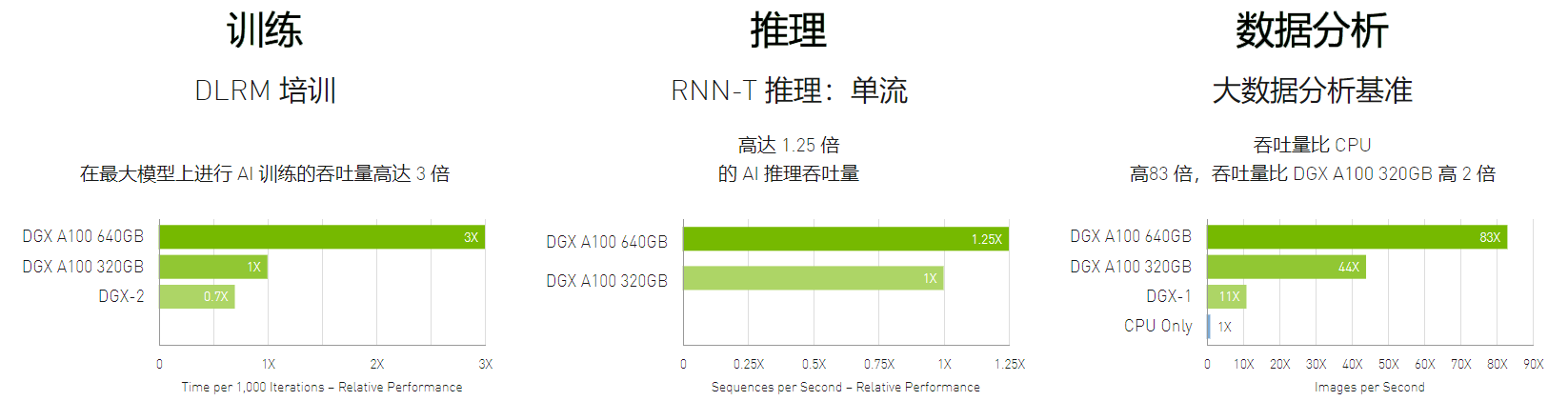
改变游戏规则的性能
NVIDIA DGX A100 内部技术
 NVIDIA A100 张量核心 GPU
NVIDIA A100 张量核心 GPU
NVIDIA A100 Tensor Core GPU 为人工智能、数据分析和高性能计算 (HPC) 提供前所未有的加速,以应对世界上最严峻的计算挑战。借助第三代NVIDIA Tensor 核心提供的巨大性能提升,A100 GPU 可以有效地扩展到数千个,或者借助多实例 GPU,将其分配为七个较小的专用实例,以加速各种规模的工作负载。
 多实例 GPU (MIG)
多实例 GPU (MIG)
借助 MIG,DGX A100 中的 8 个 A100 GPU 可以配置为多达 56 个 GPU 实例,每个实例都与自己的高带宽内存、缓存和计算内核完全隔离。这允许管理员为多个工作负载调整 GPU 的大小并保证服务质量 (QoS)。
下一代 NVLink 和 NVSwitch
DGX A100 中的第三代 NVIDIA ® NVLink ™将 GPU 到 GPU 的直接带宽翻倍,达到每秒 600 GB (GB/s),比 PCIe Gen4 高出近 10 倍。DGX A100 还配备了下一代 NVIDIA NVSwitch™,其速度比上一代快 2 倍。

Mellanox ConnectX-6 VPI HDR InfiniBand
DGX A100 采用最新的 Mellanox ConnectX-6 VPI HDR InfiniBand/以太网适配器,每个适配器都以 200 Gb/s (Gb/s) 的速度运行,为大规模 AI 工作负载创建高速结构。

优化的软件堆栈
DGX A100 集成了经过测试和优化的 DGX 软件堆栈,包括经过 AI 调优的基础操作系统、所有必要的系统软件以及 GPU 加速的应用程序、预训练模型,以及来自NGC ™ 的更多内容。
 内置安全性
内置安全性
DGX A100 为 AI 部署提供最强大的安全状态,采用多层方法,涵盖基板管理控制器 (BMC)、CPU 板、GPU 板、自加密驱动器和安全启动。
